Analyzing Financial Reports with Gemini 1.5
A potential RAG alternative?

The Gemini 1.5 Pro represents the latest advancement in the Gemini series of LLMs (Large Language Models), developed by Google DeepMind. This model stands out for its exceptional computational efficiency and its multimodal mixture-of-experts framework. With the ability to recall and reason through fine-grained information from a context comprising millions of tokens, Gemini 1.5 Pro excels in processing and comprehending extensive documents, video content, and audio recordings, as well as their various combinations.
In this article, I will demonstrate practical applications of Gemini 1.5’s new features and explain what makes it uniquely effective in multimodal settings with extended context.
Limitations of Current Large Language Models
State-of-the-art LLMs currently face challenges with context length; as input grows, it becomes increasingly difficult for these models to retain all necessary information before generating an answer. This limitation is primarily due to the nature of the attention mechanism within transformer models, but for now, we will not delve into its technical intricacies.

What sets Gemini 1.5 apart is its ability to perform near-perfect retrieval of information up to at least 10 million tokens. Remarkably, it maintains levels of performance on par with its predecessor, Gemini 1.0 Ultra, even as it handles larger context windows:

The Needle in the Haystack
In many practical scenarios, we do not require the entire context; instead, we need to extract specific points of interest from the given context. With the limited context lengths of most models, the preferred solution has been to use Retrieval Augmented Generation (RAG) techniques. RAG enables developers to divide and manage their inputs according to context limitations and identify the most relevant sections through text similarity searches. Locating the most relevant segment within a vast array of information is a formidable challenge, akin to the age-old proverbial search for a needle in a haystack.
To address this challenge, the NeedleInAHaystack test was developed. It involves inserting random facts or statements at various depths within a long context and then measuring the retrieval performance. This test helps assess the ability of a model to accurately identify and extract pertinent information, even when it is embedded within a larger and more complex context.

The performance of models such as GPT-4 and Claude-2.1 tends to diminish as the context length grows. In contrast, Google reports that Gemini 1.5 Pro achieves near-perfect recall of the “needle” (>99.7%) with up to 1 million tokens, which is a notable achievement.
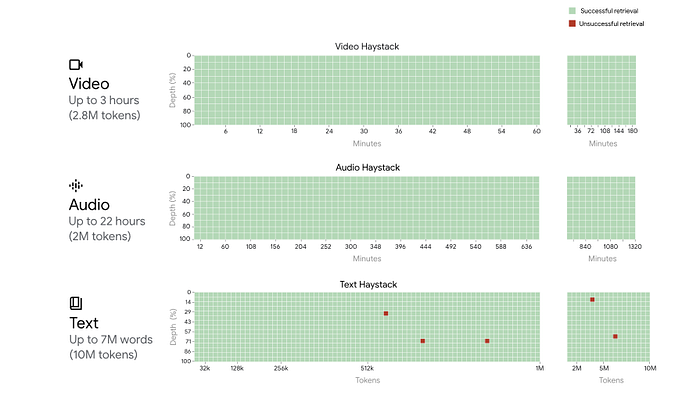
Moreover, the report indicates that Gemini 1.5 Pro maintains its recall performance across different modalities, even with increased token lengths. This consistency is an important factor when dealing with multimodal long context tasks.
While there are many technical aspects to explore, such as the mixture of experts and faster training speeds, let us now focus on a practical use case for Gemini 1.5 Pro.
A Practical Use Case for RAG and Gemini 1.5 Pro
Imagine you are an amateur investor excited about the latest advancements in the AI sector. As a forward-thinking investor, you have purchased stocks from a high-end graphics processing unit (GPU) manufacturer. At the beginning of 2024, you want to evaluate some of your investments, starting with their yearly financial reports.
After struggling for a few minutes to read the financial reports and tables, you realize that you lack both the time and financial expertise to analyze these lengthy documents filled with complex tables and jargon. You decide to use a large language model (LLM) to help you, but you soon discover that as the reports grow longer, the model begins to miss important information and sometimes hallucinates.
To solve this issue, you opt for a RAG approach. By splitting the documents into readable chunks and retrieving the most relevant pieces, you can feed your LLM with the necessary information to generate accurate answers. However, you may find that retrievers sometimes fail to provide relevant content, especially with documents containing custom table formats.
This is where Gemini 1.5 comes in. With its impressive 1 million context length and support for diverse modalities, including PDFs, it seems tailor-made for your task.
As an added challenge, consider that NVIDIA’s latest fiscal report, released on February 21st, 2024, falls outside the training data of current LLM models. Moreover, you plan to compare this almost 100-page document with its ~170-page predecessor from the previous year for in-depth analysis. Fortunately, Gemini 1.5 makes the process surprisingly simple — just drag and drop these files into your AI Studio chat, and it automatically handles the parsing and provides token counts for each document.
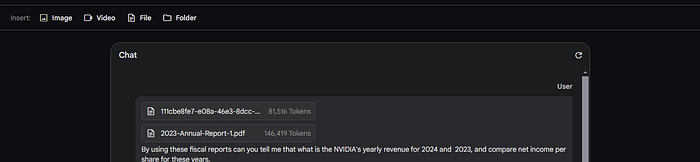
As you can see, both documents combined contain more than 220,000 tokens, surpassing the context limits of most LLM models. Now that you have uploaded both documents, you ask the most important question on your mind: “How is the company doing compared to the previous year, and how does that affect shareholder incomes?”

And just like that, Gemini 1.5 provides a clear and concise analysis, breaking down the information for you. The analysis reveals that the company is doing well and even offers insights into the reasons behind its success. Although you may not be an expert in financial analysis, you can still understand that the company’s performance is strong based on the information provided.
Feeling more confident in Gemini 1.5’s capabilities, you decide to ask another question: “What are the key factors that contributed to the company’s growth compared to the previous year?”:
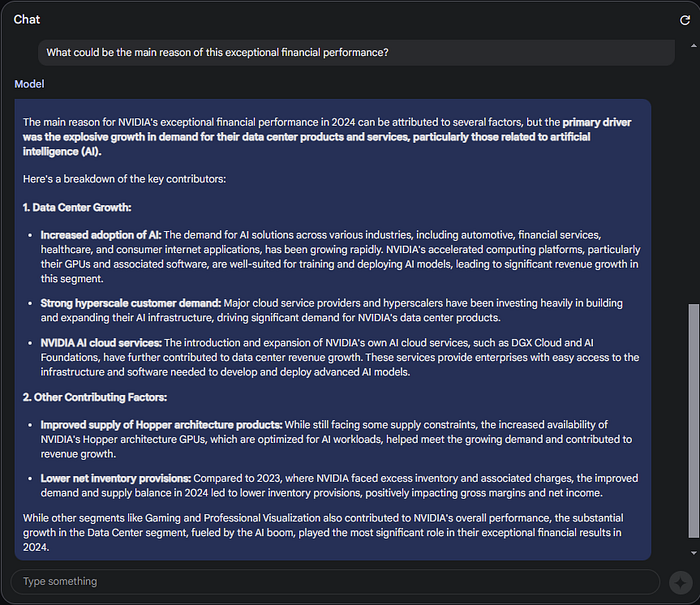
Impressive, isn’t it? It seems artificial intelligence plays a significant role — quite the coincidence!
Even better, the extended context length allows for further exploration through additional questions, adding reports from the same company or others, or incorporating financial news sources, videos, and graphics to enrich your analysis. Remarkably, even with these lengthy reports, we’ve only utilized about a quarter of Gemini 1.5’s context capacity. This opens the door for extended and in-depth conversations, enabling you to swiftly grasp complex topics.
Conclusion
Gemini 1.5, with its expanded context length and multi-modality capabilities, effortlessly fits into your daily tasks, eliminating the need for complex RAG pipelines or dealing with “hallucinations.”
However, this does not diminish the value of RAGs. They continue to be helpful in situations where feeding the entire context to the LLM involves unknown costs or when information loss through chunking is minimal. Additionally, there are really long contexts that may still require chunking. In such cases, Gemini 1.5’s longer context length allows for feeding larger chunks, which is another advantage for more complex RAG systems.
The immense context length of Gemini 1.5 is truly promising, and I am excited to see how longer context models with MoE’s develop in the future.
